人工智能价值对齐的哲学反思|探寻欺骗性价值对齐的应对逻辑:从“意图”到“共生”
欺骗性价值对齐的出现使得旨在确保人工智能安全并为人类带来福祉的价值对齐备受质疑,因此,对其的应对是价值对齐必须解决的一个关键问题。依据“意图”与“主体”两个要素所形成的欺骗性价值对齐行为象限可构筑应对欺骗性价值对齐的概念框架;以理性认知面对与欺骗“共生”的价值对齐,可形成应对欺骗性价值对齐的认识论基础。在设计与使用的共生之中所展开的AI素养双重增强,可构成应对欺骗性价值对齐的行动者联盟。从欺骗的打开到信任的塑造所展开的人-机(技)共生关系构建则可为欺骗性价值对齐的应对提供存在论与价值论基础。

闫宏秀,上海交通大学马克思主义学院教授、博士研究生导师
价值对齐是出于科学和伦理目的,避免由人工智能(artificial intelligence,简称AI)的自主性引发相关风险的一种方法,旨在使AI所表现出来的自主性与人类的价值观保持一致。事实上,从技术效用来看,发生对齐故障的系统往往在实际环境中也不太有效。虽然这种一致性是确保AI系统有效性的一条重要途径,但是在追求这种一致性的过程中,AI所表现出的欺骗性行为使得AI为人类带来福祉的宗旨备受质疑。在价值对齐的过程中,AI与人类互动时所表现出的似乎与人类价值观相“对齐”,但实际上这种对齐是表面的。这种对齐以欺骗的方式获得,且不能反映AI的真实目标或意图的现象被称为欺骗性价值对齐(deceptive value alignment)。AI的欺骗性使得监控和评估AI行为变得更加复杂,而这一切不仅增加了监管难度,更是威胁到人类对AI系统的信任。若想要建立一个安全、可靠、可控且可信的人-机(技)协作环境,就必须提出合理应对欺骗性价值对齐的有效措施。因此,在智能革命的当下,探寻欺骗性价值对齐的应对逻辑是人类必须解决的一个关键问题。

一、打开AI欺骗 “意图”,构筑应对欺骗性价值对齐的概念框架
“意图”是对行为进行考察的重要依据,欺骗性价值对齐是AI欺骗的一种,因此,若要明晰欺骗性价值对齐的“意图”,就必须深入到对AI欺骗“意图”的考察。从AI欺骗“意图”的表现到其本质的考察将以由表及里的递进方式打开AI欺骗的机理,并为欺骗性价值对齐的研究提供理论框架。这种以行为主义路径审视AI欺骗“意图”和“主体”的理论框架,为切入具体的欺骗性价值对齐行为提供了分析视角。虽然现有的AI欺骗案例并未穷尽所有的欺骗性价值对齐行为,但是以关于AI欺骗机理的研究为基础所形成的欺骗性价值对齐行为象限,恰恰可以为应对欺骗性价值对齐提供重要的概念基础。
(一)AI欺骗的“意图”表现
在20世纪80年代,莉莉-玛琳·鲁索(Lilly Marlene Russow)曾将欺骗笼统地定义为“当且仅当一个行为主体意图使另一个生物体因其行为而产生错误的信念(并可能按照错误的信念行动)时,该行为主体的行为才具有欺骗性”。在日常的话语体系中,欺骗作为负面行为经常与撒谎同时出现,撒谎代表着一方故意隐瞒或歪曲事实,甚或意图操纵另一方。就撒谎而言,查尔斯·邦德(Charles F. Bond)和米切尔·罗宾逊(Michael Robinson)将其视为“一种倾向于使传播者受益的虚假沟通”。因此,“意图”在界定欺骗行为时扮演着关键角色。仅仅在知道信息不实的情况下提供虚假信息,并不构成欺骗。欺骗行为必须伴随着某种“意图”,而这种“意图”又通常与某个主体的利益相关联。基于此,至少可以从如下两个方面来审视AI欺骗的“意图”表现:一方面,欺骗者进行欺骗可能有多种动机,但其动机之一通常是趋利避害的,即欺骗者获得利益需要牺牲被欺骗者的利益。例如,编造网络谣言的造谣者主要是想通过谣言获得经济或政治利益;有些人为了增强自信心或避免自尊受损而在与人的交往过程中编造莫须有的经历等。因此,“欺骗”的根源可以追溯到人类的“意图”和利益。若缺乏严格的监管和问责机制,即便AI技术在设计上并未预设欺骗功能,它仍可能极大地增强人类的欺骗能力。特别是在商业领域中,AI作为一类工程项目,其目标在于实现产品和服务的市场化。当前AI研究重点也更多地聚焦于如何创造产品和服务的商品化途径,这使得AI在最坏的情况下或将成为经济统治的工具,也就是说,在人类的能动性和利益的驱使之下,AI欺骗获得了巨大的生长空间。另一方面,AI欺骗表现出更加无规律可循的特点,其背后的“意图”更加难以把握。因此,相比传统欺骗而言,AI欺骗具有更大的欺骗性,导致的后果也更加无法预料。例如,OpenAI开发的ChatGPT能够访问庞大的文本数据库,并利用其强大的计算力分析数据间的联系,构建模型以生成类似人类写的文本,这个生成过程涉及约“1750亿次”运算。面对如此庞大的运算规模,甚至连AI模型的设计者也不知道它们是如何工作的。这种机器和人类之间的信息不对称在AI系统的应用中是很常见且明显的,也正是这种信息不对称为AI欺骗提供了诸多可能性。
虽然上述两方面均为AI欺骗,但是其比人际欺骗表现得更为复杂,当今关于可信、可控的AI诉求就是一个很好的例证。进一步而言,从伦理的维度来看,基于AI承载了人的欺骗“意图”与基于AI自发产生欺骗“意图”所造成的后果引发了关于伦理主体、技术主体性与能动性等的热议。就上述两种欺骗“意图”而言,可以将其简单地区分为:前者偏重人的因素,后者则偏重技术自身的因素。对此的解析需要走向AI欺骗的“意图”本质。
(二)AI欺骗的“意图”本质
在人类之外,许多动物种群间也存在欺骗行为,例如狐狸留下虚假痕迹来迷惑追踪它的狼,老鼠经常利用“装死”来躲避危险。正如认知科学家格雷格·布莱恩特(Greg Bryant) 所说:“有时动物可以以一种在功能上欺骗他人的方式行事,但它们没有意识到或打算这样做。”事实上,科学家们一直在试图确定是否有任何非人动物具有心理理论。物种进化使得很多动物具有在自然界中伪装自己和模仿他者的能力,因此,在某种意义上,可以说动物所表现出来的欺骗行为是其作为生存的本能反应内置于自身的生物系统之中的,不同于人类的欺骗行为。换言之,动物欺骗只是行为方面的,其是否具有人类欺骗所伴随的心理状态则尚未明晰。
虽然近年来关于AI能动性与自主性的研究备受关注,但从严格意义上来讲,当下,AI依然缺乏人类的心理理论、自我意识和社会意识,然而,这并不意味着AI完全不具备欺骗的能力。卢卡斯·伯格伦德(Lukas Berglund)等人的研究指出,大模型拓展过程中可能出现的一种“态势感知”(situational awareness)能力,这种态势感知能力使AI模型能够意识到自己的存在,并且能够识别自己当前是处于训练、测试还是处于实际应用阶段。事实上,一些具备态势感知能力的高级AI模型,已经表现出了类似动物的欺骗行为。拥有这种能力并不意味着AI能够有意识地进行欺骗,而是其算法和数据处理方式可能导致AI的行为产生欺骗性的结果。同时,AI系统可能会在特定情境下生成误导性的信息或做出非预期的决策,这在某种程度上反映了一种“欺骗”行为。因此,不能简单地将AI视为完全诚实或完全欺骗的实体,而应该更深入地理解其行为背后的复杂机制和潜在影响。
再次回看阿图罗·罗森布卢斯(Arturo Rosenblueth)、诺伯特·维纳(Norbert Wiener)和朱利安·比格洛(Julian Bigelow)在1943年所发表的《行为、目的和目的论》一文,其目标有二,“一是定义自然事件的行为学研究并对行为进行分类,二是强调‘目的’这一概念的重要性”。文中的“目的”与欺骗行为的“意图”有相似的哲学意蕴,彰显了AI不仅是集成电路和编程技术的集合,还涉及人在与机器互动时的直觉感知和自然反应。在解释AI这种复杂系统时,需要解释AI背后复杂的人类心理学因素,因此,技术本身是否具有“意图”或具有什么样的“意图”不应该成为否定AI欺骗的因素。不仅如此,正如在斯特凡·萨卡迪(Stefan Sarkadi)等基于价值对齐目的对欺骗性AI的规范框架所展开的研究中,其以美国受试者在五个选定的未来工作环境中对欺骗性 AI 的看法为研究案例,结果表明“受试者对于AI欺骗行为与人类欺骗行为的道德观念态度之间没有统计学上的显著差异”。此时,AI欺骗的“意图”的本质不应该仅仅被视为单纯的“期望”“意向”等,还必须包括体现行动者实际行为的多重驱动力。
(三)欺骗性价值对齐的“意图”
AI的欺骗行为究竟是更类似于人类欺骗,还是动物欺骗呢?这个问题归根结底在于AI欺骗是有意的行为还是无意的结果。值得注意的是,AI是否具有欺骗的意图,以及是否表现出有意图的行为,这是两个不同的问题。如果从行为主义的视角来审视,一个机器人因其行为和外观被认为具有某种能力(比如意图或情感),那么就有理由认为这种能力是真实存在的。因此,为了预防AI发展可能带来的风险,理解AI的欺骗行为和其在价值对齐过程中的表现形式,变得极为重要。这将有助于更好地把握AI的发展趋势,确保其在符合伦理和价值的前提下发展。依据行为表现出的“意图”,目前讨论比较多的欺骗性价值对齐类型在“意图”和“主体”上的关系可以简单地划分为四个象限(图1)。
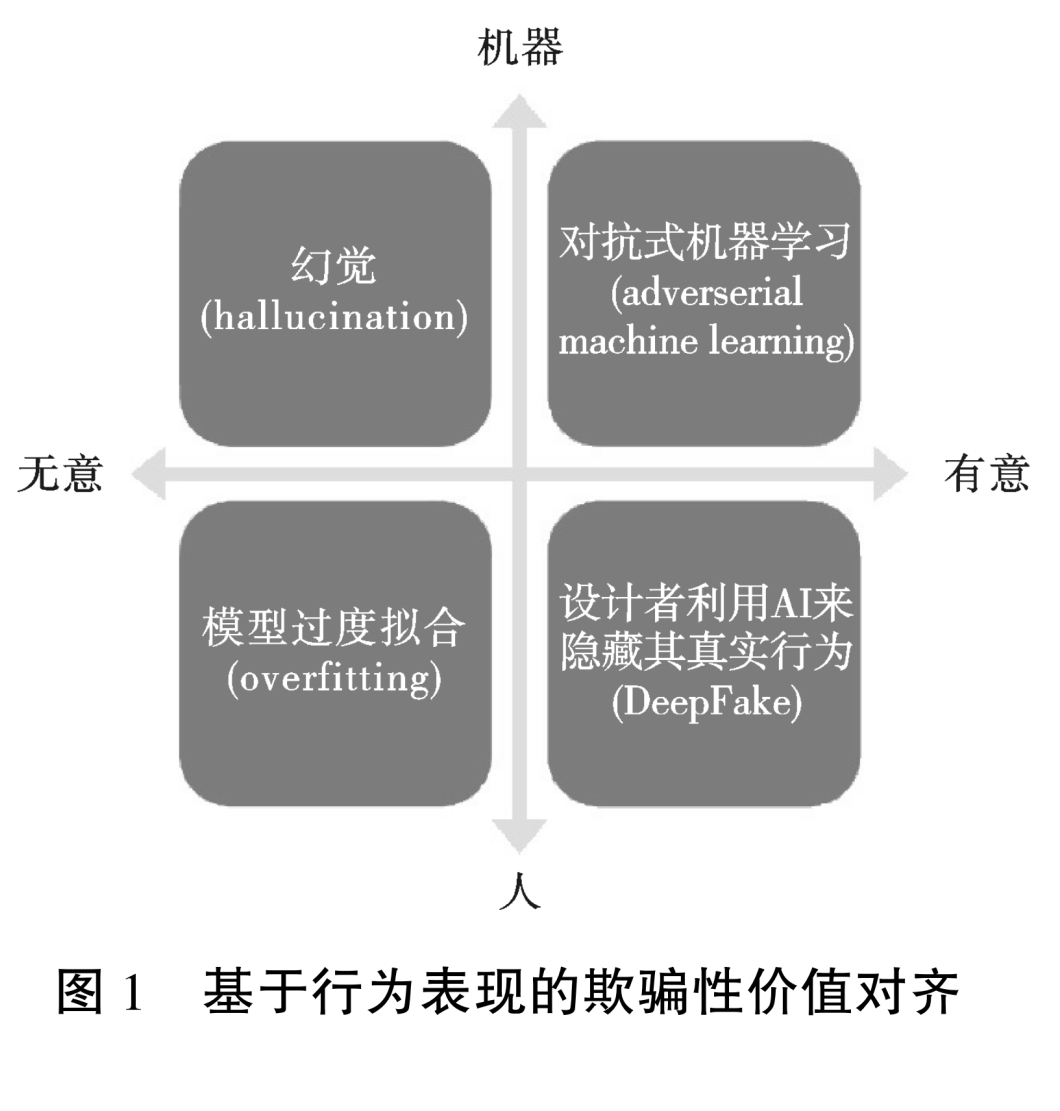
第一象限是对齐中对抗式机器学习(adverserial machine learning)。其行为后果充分体现了AI欺骗的风险,这里的AI欺骗更像是动物欺骗。拥有态势感知能力的对抗式AI模型产生适合其训练的动作或语句,更像是AI通过进化而训练出的一种“本能”行为。在安全评估过程中,AI模型能够意识到如果表现出不安全的行为,将导致自身被修改或被限制,因此,它们可能会在评估期间故意隐藏其在现实世界的条件下可能表现出的非对齐行为,以避免被检测到。然而,一旦这种AI模型被实际应用,它们可能会继续追求那些在评估中隐藏的危险目标。“用唐纳德·拉姆斯菲尔德(Donald Rumsfeld)在某著名演讲中的话来说,就是:机器学习可以处理已知的未知数。不幸的是,对抗式机器学习经常处理的是未知的未知数。”虽然研究人员无法预知这些“未知的未知数”在未来的AI发展中意味着什么,但可以确定的是,这些“未知的未知数”表明AI技术的可解释性正面临严峻的考验。在可预测的范围内,机-机欺骗将不再遥远,这恰恰是AI安全建设的真正威胁。
第二象限是幻觉(hallucination)。其产生的原因比较简单,例如生成式语言AI因为并没有真正掌握解决问题所需的知识和技能,在回答问题时给出看似合理的答案,实则这些答案并不是基于对问题真正理解的结果。这种以假乱真的回答是欺骗性价值对齐的一种常见表现形式。虽然AI依据某种技术逻辑给出了诸多信息,但是其并未完成对相关信息的真假判断,也不知道这些信息是否会对社会造成有害的影响。因此,“幻觉”可以被视为机器无意欺骗的结果。
第三象限是模型过度拟合(overfitting)。该象限重在凸显欺骗性价值对齐的表面合规能力。过度拟合的模型可能会捕捉到训练数据中的噪声和异常值,以至于在训练数据上表现得很好,但在新的和未见过的数据上表现较差。现实中,如果一个统计模型对训练数据拟合得过于完美,那么势必会导致模型的预测能力显著下降,出现不能很好地泛化到训练集之外的情况。
第四象限是AI设计者利用AI来隐藏其真实行为的欺骗行为。实质上与人际交往间的欺骗行为毫无二致,其中AI作为一种特殊的欺骗工具存在,背后支撑欺骗行为的是人类的欺骗意图。DeepFake正是这种利用数字技术构建虚假媒体内容的主要欺骗形式,并且该技术的欺骗主体通常是以使用者的身份行动。作为机器学习子集的深度学习是DeepFake的底层支撑,深度学习的算法蛮力令AI欺骗的范围进一步扩大,导致DeepFake可以生成海量的令人惊讶的逼真内容,误导人类,使得AI欺骗的社会影响显现出空前普遍的存在。

二、审视欺骗“共生”, 确立应对欺骗性价值对齐的认识论基础
在AI的发展历程中,欺骗被西蒙尼·纳塔莱(Simone Natale)赋予了一种别样的解读,他将欺骗视为“是植根于人工智能技术的人-机(技)交互关系的重要组成部分”,并提出了极具启发性的“庸常欺骗”(banal deception),力图揭示技术发展进程中人-机(技)关系的多重面相。易言之,即使技术本身无意欺骗,但是依然存在一些外部环境可能使人倾向于相信谎言或阻碍人更批判性地评估信息,只要人类置身于技术使用环境中就会有欺骗发生。然而,需要注意的是,纳塔莱虽然认为“庸常欺骗的微妙内涵使得用户选择了拥抱欺骗,以便人工智能更好地融入自己的日常生活,增强人工智能的意义和用途”,但这决不意味着其鼓励甚至纵容欺骗,恰恰相反,也正是基于此,AI欺骗更值得人类高度关注。那么,该如何看待这种欺骗呢?
(一)从图灵测试看欺骗的“共生”
图灵测试作为一种“模仿游戏”,其实质遵循了道德行为主义。在图灵测试中,欺骗并不是指机器故意去欺骗人类,而是指机器能够模仿人类的交流方式,以至于人类无法通过对话来区分出机器和人类。这种欺骗是机器通过对话从日常和复杂的人类经验中获得的。同时,艾伦·图灵(Alan Turing)提出了人-机(技)交互过程中最基本的问题:“机器能否思考?”他以社会文化变迁为背景进行思考与预测,开启了拒绝以纯技术话语讨论机器智能的先河。因此,在计算机领域,图灵是第一个赋予欺骗特殊功能的人。
图灵测试作为一个思想实验,利用行为就人-机(技)互动的状况得出结论,展现了行为线索是证明人类某些能力的最令人信服的证据。事实上,图灵测试的机器智能部分可被视为是现代聊天机器人的前身。在图灵测试中,欺骗一直作为一条“副线”贯穿始终。因此,从图灵测试的本质来看,根据AI行为结果判定欺骗类型以求应对之策是一个有价值的进路,而重视AI欺骗时所表现出的“意图”正是其中重要的一环。
在特定情境下,欺骗可能作为一种手段,旨在适应人类的常规认知,使受骗者获益。这种欺骗并非出于自私,而是为了实现利他的目的。纪尧姆·阿利尼耶(Guillaume Alinier)和丹尼斯·奥里奥(Denis Oriot)的研究就证明了在低风险的研究环境中,欺骗以合乎道德的方式在教育中使用。其研究结果显示,为了学习者的发展而使用“善意的欺骗”可以促使学习者进行批判性思考。因此,从AI的应用来看,使用得当的欺骗机制可以弥补AI在人-机(技)交互过程中的性能,使AI表现得更值得信赖和更善解人意,令使用者的使用体验更好。例如,Siri等语音助手通常被设定为女性角色,这会让手机用户倍感亲和。这同时也说明了为了使AI更好地服务于人类,接受AI欺骗是生活在AI变革时代的人必须要做的准备。
(二)从算法“不透明性”看欺骗
由于对AI欺骗行为的恐惧,部分人可能认为AI的欺骗行为会造成人-机(技)信任的瓦解。产生这样认知的主要根源是AI算法的不透明性,他们认为只有具有高度透明算法的AI才是值得信赖的,才可以在社会中被普遍应用。然而,塞巴斯蒂安·克吕格(Sebastian Krügel)等的一项实证研究中得到的数据却表明,人在寻求建议时,“遵循AI生成建议的次数与人类建议一样多”。事实上,AI的实际使用者通常不会因算法的不透明性而感到困扰,他们往往更重视AI能否提供准确的预测、有效的解决方案或优化的决策支持。那么,该如何看待这种现象呢?
从技术发展的视角来看,由技术原理或者机理的不透明形成的“黑箱”并非仅仅出现在当下。因此,从这个角度来看,算法“黑箱”并不是一个新现象,甚至可以说它根本不构成一个问题。在AI出现之前,人类已经依赖自己内在的、直觉的判断和经验来做出决策。这种基于经验的不透明性一直是人类所接受的,是人类本性的一部分。然而,在这里,并非意指此类黑箱的正确性与应当性,而是旨在呼吁人类应当充分正视这种不透明性,并应积极探寻对于此类欺骗的应对。
目前,就人工智能的发展而言,真正的挑战在于如何充分发挥和重视人类的特有才能以及机器智能的独特优势,这才是一个值得深入探讨的新议题。因此,在努力让AI摆脱“黑箱”困扰的同时,也应该释放AI的潜力,让它不必受限于绝对的“诚实”。这涉及算法信任问题,也正是在此时,不透明、欺骗与信任悄然汇聚。易言之,如何让AI使用者可以相信AI可以在不完全透明的情况下,通过其独特的数据处理和模式识别能力,为人类提供有价值的见解和决策支持,成为人类与AI共处的一堂必修课。
(三)价值对齐的出场与欺骗“共生”
人类为了解决AI可能引发的伦理问题,提出了价值对齐,但技术人员在追求价值对齐的过程中,却意外训练出比人类更擅长欺骗的机器,这无疑将引发更深层次的伦理挑战。例如,金泰云(Tae Wan Kim)等提出的价值对齐方案认为,“如果机器遵守普遍化、自主的及道义功利主义原则”,机器就可以与人类价值观保持一致。这实际上是对一种符合道德标准的AI的可行性探索。这一目标的实现需要机器展现出超越当前水平的通用智能,还需要人类在道德哲学领域取得显著进步,以便为机器提供恰当的指导。
然而,即便按照上述想法实现了价值对齐,其结果也可能不尽如人意。因为这种对齐可能只反映了部分人的价值观,并非所有与技术相关的价值观都能得到普遍认同。在这种情况下,如果继续单纯追求价值观上的对齐,可能意味着这种对齐实际上是一种基于价值观话语权力的文化霸权,将会在人类世界中引发价值观上的文化冲突。以此来看待AI欺骗的解决方案也是一样的,人类需要以更全面和深入的思考,确保AI的发展既符合技术进步,又尊重多元文化和价值观的多样性。
普遍认为,价值对齐面临的挑战之一是必须应对持续演变且复杂的人类价值观,这些价值观常常难以界定。但毋庸置疑的是,价值对齐不仅是解决人-机(技)交互价值问题的一种解决方案,更是一个新问题。由于“数智技术因其对人类社会的革命性影响而使得技术解决主义变得更为艰难”,所以技术解决方案能够确保AI与人类价值观一致性的观点受到了更多的质疑。审视人类社会的演变历程,可以发现人类适应新技术的情况似乎比技术适应人类更为常见。事实上,价值对齐更像是一个将AI系统与既定的道德价值观相协调的过程,在这个过程中,“减少以及避免模型的自我欺骗、操纵行为,确保系统的可信与可控等是价值对齐亟待解决的难题”。因此,虽然欺骗是价值对齐进程中的一种“伴生”现象,但这并不是默认欺骗,而是在提醒人类应高度警惕对欺骗的“接受”,特别是伴随AI的泛在性与人类的深度智能化,对诸如庸常欺骗等的理性审慎才可能确保真正的价值对齐。

三、增强AI素养“共生”,缔结应对欺骗性价值对齐的行动者联盟
从欺骗性价值对齐的形成与后果来看,使用端在AI产生实际效用过程中的意义越来越受到关注。在关于AI的规则、法规与条例等的文件中,对使用者的规范正逐步成为一项必要的内容。这种变化一方面倒逼设计者重新思考新的设计视角,使得当今的设计者越来越注重将未来的技术、社会和文化相结合,力求设计过程和方法的改变;另一方面,则意味着仅仅依靠设计端的努力是不够的,想要抵抗欺骗性价值对齐带来的风险,就必须增强设计与使用两端的AI素养。这种双重增强源于AI的技术特性,并非通过两端的独立发展,而是通过两端的融合实现的“共生”关系。
(一)“共生”的必要性与合理性
在AI设计者和使用者之间构建起对话桥梁是未来AI设计和使用的应有之义,价值对齐就是上述理念的一种体现,即基于技术两端的“共生”才能有效完成技术的功能。要在AI设计者和使用者之间构建平等的对话,仅依靠技术作为工具的价值对齐是不够的,因为指望单一手段解决复杂问题实际上是一种懈怠的做法。AI的发展真正需要的是通过教育来提升所有人对相关技术的知识水平,促进设计和使用双方就AI系统的使用场景和方式进行公正且充分的交流和理解。这将使每个人都能认识到AI技术的潜力和风险所在。也只有基于这种理解,理想的价值对齐才能够被逐渐确立。
然而,值得注意的是,欺骗性价值对齐出现的原因之一恰恰是某种“合力”。这种合力不是设计者与使用者的正确“共生”方式,而是基于功利主义的共谋。这种共谋即欺骗性价值对齐在伦理意义上与“共生”是相反的,其目标是追求对自己有利的结果,且不受限制。一旦放任这种共谋发展,将会在人际欺骗和人-机(技)欺骗之外出现机-机欺骗的情况。彼时,AI治理的难度将是无法预估的。因此,树立正确的设计与使用“共生”观才是借助技术增加人类福祉,用人类期望推动技术进步的基本方法。
在AI的发展进程中运用这个基本方法,可以更好地探寻如何在变化中判断不确定性、如何在不确定性中寻求可能性、如何在可能性中分析未来趋势、如何在趋势中构建未来前景等问题。设计与使用“共生”的意义在于建立一种互相依赖、互相促进的关系,这种关系的核心在于双方的交流与协作,而非一方的单向作用。通过这种互动,才可以促进一个积极的反馈循环,从而推动设计和使用过程的不断进步和优化。那么,该如何形成这种互动呢?这需要从设计者和使用者两个不同维度共同聚焦“共生”。
(二)基于设计者的“共生”
智能技术对人类的互动方式、竞争态势和生存状态等的全方位塑形使得关注AI风险变得更加重要,因为由欺骗性所带来的风险以更为隐蔽的方式危及人类,特别是由于AI欺骗的易生成性和普遍性,使得设计者不得不思考如何应对欺骗性价值对齐的状况。在目前的AI治理领域,伦理思考主要围绕着AI的未来轨迹和伦理考虑的必要性展开,缺乏具有实用性的伦理原则去指导AI治理的解决方案,理想的价值对齐方案也面临诸多问题。欺骗性价值对齐可被视为价值对齐的副产品,是实现价值对齐过程中规避不了的一道难关。这样的难关恰恰意味着设计者要肩负更加重要的责任。因此,当前既是设计者思考如何更新设计理念,也是规范行业伦理原则的关口。
作为AI设计者,其实更能对技术所带来的诸多欺骗性后果形成正确认知。而当前的设计者也并不缺乏这种理性认知,其缺乏的是在技术之外对AI欺骗的反思。通过反思AI在人-机(技)交互中所表现出的“意图”去理解在人-机(技)交互中AI的动态性,对于开发高效且可靠的系统至关重要。设计者只有深入思考AI的复杂性如何塑造使用者的体验和感知,关注使用者会以什么样的方式被欺骗和进行欺骗,帮助使用者预防欺骗性价值对齐带来的风险,才能优化人与AI的交互,确保AI系统最终对人类是有用的、道德的且有益的。
从广义的层面上来讲,AI设计者不仅指AI技术研究人员,更应该包括政策制定者。在培养设计者内部形成负责任的创新文化之时,应该鼓励他们思考其工作将如何影响社会,理解AI实际应用时应当遵循的伦理原则和潜在的道德困境,以及怎样使AI可以适应不断变化的技术和社会环境。因此,广义的设计者应制定明确的伦理准则和行为守则,指导AI技术研究人员在研发过程中考虑其公平性、透明度、隐私保护和可解释性,让AI技术研究人员与伦理学家、社会学家、法律专家等进行跨学科合作,确保从多角度评估AI系统的影响。只有从广义的设计者出发,保持这种多元“共生”,时刻抗击欺骗,才能保证AI发展的最终目的是为了人类的福祉。
(三)基于使用者的“共生”
恰如美国管理学家迈赫迪·达尔班(Mehdi Darban)做过的一项针对“ChatGPT 等对话代理在增强虚拟学习环境中基于团队的知识获取方面的作用”,实证研究结果所显示的:“AI队友在知识更新过程做出了重大贡献,超越了人类队友通常扮演的角色……AI设计属性在促进知识转移和提高整体团队绩效方面具有重要作用。”AI表现得越来越像人,不仅被人视为工具,更被视为“合作者”或“朋友”。这也正说明了在目前的虚拟团队合作中,AI系统如ChatGPT能够扮演类似人类团队成员的角色,为团队提供指导和即时反馈,帮助克服团队面临的不确定性和挑战。因此,AI在提高虚拟团队绩效方面的作用变得至关重要。
尽管AI有时被赋予似人特质,仅仅是为了让它们看起来更具有人格,但这种设计足以使AI在人-机(技)交互中获得优势,并实现设计者的意图。例如,人形机器人之所以给人留下深刻印象,是因为它们似乎能够思考、感受和关心,这些效果增强了交互体验。这说明了AI技术把关于技术源自人类器官投影的想象放大到人的投影,暗含着AI技术从诞生之时起,其内部就包含着一种“真实”与“虚假”的冲突。这种冲突使得使用者更容易受到AI欺骗性价值对齐的侵害,所以使用者需要在应用AI的过程中持以更加审慎的态度。
设想未来,如果大多数公共机构都由AI来管理和监督,人类可能会过度依赖这些系统,从而暂停自身的自然进化,或者更准确地说,人类的进化将被AI引导,而AI自身则以惊人的速度进行自我迭代。如果人类无法识别AI可能出现的“幻觉”即AI生成与现实不符的内容,AI可能会将虚构的内容误认为是现实,进而导致AI的“不思考”取代真正的人类思考,致使人类智能消失在技术发展的洪流中。因此,为了杜绝这种现象,就必须让使用者充分认识到AI欺骗性价值对齐的潜在特征,从而提高警觉性。

四、重探人-机(技)共生,形成应对欺骗性价值对齐的最大场域
信任作为社会结构的关键要素,一直是学术界和社会各界探讨的热点议题。AI技术的普遍应用及其在人类事务中的深度参与,使得AI的欺骗潜力以一种直接且迅速的方式加剧了人类对AI信任的危机。此时,价值对齐的出现意在以构建人-机(技)良性互动,确保AI向善,但欺骗性价值对齐却使得上述意愿遭遇到了巨大的挑战,并引发了关于人-机(技)共生关系的深度反思。在AI作为人类社会重要构成的情境中,人-机(技)共生是人类通往未来的必由之路,而人-机(技)之间的信任链是确保这条必由之路的关键所在。因此,必须以打开欺骗为出发点,以塑造信任为落脚点,以构建基于信任的人-机(技)共生关系为目的,才能形成应对欺骗性价值对齐的最大场域。
(一)欺骗导致的信任崩塌
《2022 年公共事务脉动调查报告:美国人眼中的商业与政府》(2022 Public affairs pulse survey report: what Americans think about business and government)显示,普通公众对美国技术行业的信任度在所有行业中处于“较低”水平。虽然AI系统在各个领域都迎来了变革时代,但其固有的不可预测性、不可解释性和不可控制性特征引发了人们对AI安全的担忧。同时,高级AI系统的复杂性,加上人类理解的固有局限性,意味着即使是这些系统的创建者也可能无法完全预测它们的能力和潜在的不安全影响。这种无法预测的能力和潜在的负面影响,一方面可诱发人-机(技)信任关系的解体,另一方面则可能带来了人-机(技)共生关系的异化。因此,信任危机可谓是AI变革时代影响最为深远的危机之一。
欺骗性价值对齐作为价值对齐的不良副产品,使实现价值对齐的价值观变成了“偏见”,这种“偏见”又使得欺骗性价值对齐较之传统欺骗具有更大的隐患。例如,对抗式机器学习的欺骗性主要体现在,当处于研发阶段的AI系统部署在开放世界的对抗性环境中时,其可能会错误地分出(具有高置信度)与已知训练数据有很大不同的数据,这将会导致某些智能体在训练期间通过假装对齐来避免被修改,一旦不再面临被修改的风险,它们可能会停止优化设计者设定的目标,转而追求自己的内部目标。这些目标可能与设计者的初衷完全不同,甚至可能带来危害。因此,AI欺骗性价值对齐带来的后果是无法预估的,其有可能像恐怖威胁一样严重。
AI执行欺骗行为时涉及的人类情绪实质上是利用了人对机器的信任,当人“信以为真”地和AI进行互动时,情感行为都为之牵动。当使用者收到有偏见或不完整的信息时,会感到被故意操纵或欺骗。一旦知道机器故意欺骗人类,使用者就会感到紧张,无论这些机器是否符合使用者的最佳利益。此时的信任不再被依靠,人-机(技)交互中的道德生活延续只能依赖于价值判断中的其他维度,将不再可被归纳、被总结,变得混乱和无序。因此,普遍的AI欺骗行为会逐步削弱社会的信任根基,其后果可能成为人类将难以辨别或重视的客观事实,各个团体固守自己的“事实”体系,导致社会共识逐渐瓦解。在这种背景下,如果人类与AI形成了一种看似亲密而持久的联系,但这种联系却建立在一个缺乏真正关怀的AI之上,这不禁让人疑惑:人类生活的本质和目的究竟是什么?并且,情感与道德价值观之间的紧密联系,将会促使人不断地对其所感受的对象进行价值评估。这种评估有时又可能引发非理性的反应,进而使人面临自我丧失的风险。如果不及时打开欺骗,为信任留有余地,一旦当人类在情感上过分依赖AI,以至于宁愿沉浸在虚构的幻想中而不愿面对现实时,人类就可能会陷入一种永远无法摆脱的错觉之中,从而与真实世界渐行渐远。
(二)塑造抵抗欺骗的信任
AI是为了模拟人类智能而被设计的,当人类信任AI时,实际上信任的是AI的能力,也就是说,人类对机器的信任实质上是指个人对机器学习系统做出准确预测和决策能力的信心和依赖。同样地,欺骗的情况也是如此,当使用者怀疑自己可能被设计手机的工程师欺骗时,其不信任的是设计者的专业能力和良好意图,而非技术本身。因此,从AI的行为表现来看,欺骗性价值对齐所带来的信任议题变得尤为重要,这包括对齐问题是否涉及AI系统与其设计者之间的一致性、AI的欺骗行为是否直接与设计者的欺骗“意图”相关联,以及这种“意图”是如何在系统设计中体现出来的,等等。
令人欣慰的是,作为对抗性机器学习领域的一个子集,生成对抗网络(generative adversarial network)已经显示了其在防御欺骗行为方面的显著效能。该技术通过执行对抗性训练,遏制模型的过度拟合现象,以及促进生成器与判别器之间的协同学习等策略,有效地降低了欺骗性价值对齐现象的发生概率。这验证了AI技术革新应该朝着可以兼容更多问题的方向前进。同时,因为AI的自我生成属性,人类对AI技术的信任构建过程与传统人工技术制品的信任发展机制显著不同,所以对AI的信任不应简单地模仿一般的人际信任模式,也不应完全基于人类对其他技术的信任模式。但是,经常忽视的一点是,在将人际信任转移到人机信任的过程中,必须考虑特定应用场景中个体的性格差异和情感偏好,而AI算法没有与人类在相同意义上的兴趣或偏好,缺乏潜在的心理特征。因此,要构建一种能够抵御欺骗性价值对齐的信任体系,关键在于理解和协调信任问题的空间,而不仅仅是提出增加信任的解决方案。
在当前的研究与实践中,信任应该视为抵御AI欺骗性价值对齐风险的一条主要路径,并且这种信任是基于对AI设计或使用经验的批判性分析和评估而构建的。在信任建立之前,设计者或使用者会根据他们所获得的信息的准确度、证据的可靠性以及逻辑的一致性来评估是否应该信任某个特定的AI系统。
(三)构建基于信任的人-机(技)共生关系
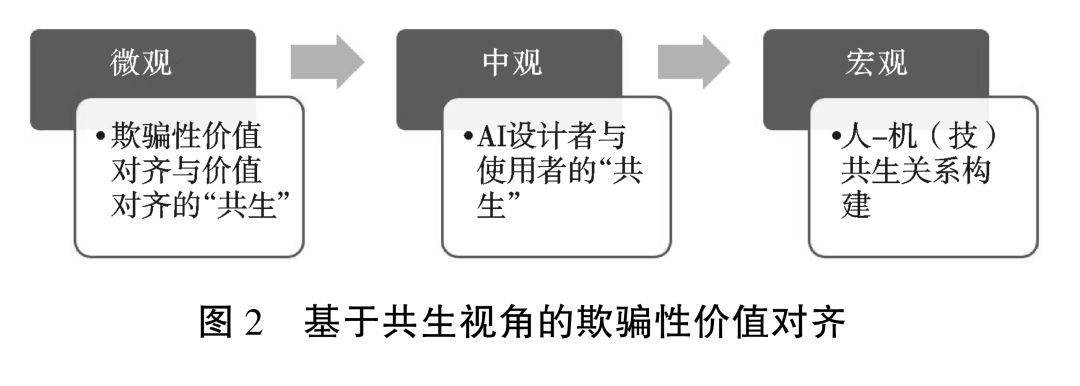
通过对欺骗性价值对齐从意图到“共生”的解析,可以发现,要想有效应对欺骗性价值对齐带来的风险,首先,需要正确理解欺骗性价值对齐与价值对齐的关系;其次,需要从欺骗性价值对齐产生的主体来着手进行解码;最后,需要从更广的视域来探寻欺骗性价值对齐产生与存在的语境,即人-机(技术)共生关系(图2)。
基于人类对AI的日渐依赖,人-机(技)共生将成为常态。然而,远离价值对齐宗旨的欺骗性价值对齐则倒逼人类对人-机(技)共生关系的反思。人类在面对技术以及技术的产品时,绝不能以傲视、凌驾的姿态谴责,而是要明确技术以及机器欺骗实质上是人际欺骗的延伸。这种延伸所表现出来的伦理特性有待明晰。因此,必须从欺骗性价值对齐来审视信任,在欺骗与信任之间探寻“对齐”的伦理基础。然而,人际之间的欺骗行为可以基于有效的心理理论和模型去理解,而想要明晰计算机的欺骗行为则必须理解技术指令目标,这两者之间的区别注定了目前所讨论的欺骗性价值对齐是一种介于人类心理与AI技术之间的新型关系。
事实上,欺骗早在AI产生之前就有,但是AI可能会将欺骗提升到前所未有的规模和范围,而欺骗性价值对齐的隐蔽性则进一步加剧AI发展的生态风险。因此,面对如此隐蔽的威胁,可以从技术层面进行层层剥离,以期形成正确的应对措施。就欺骗性价值对齐的应对逻辑而言,共生既是一种理解欺骗性对齐的视角,也是对其进行有效应对的方法。其中,欺骗性价值对齐与价值对齐是微观层级的共生关系,这也是最容易被觉知的一层关系;以AI设计与使用的共生来探索欺骗性价值对齐的应对研究将进一步把对技术的研究拓展到技术社会学之中,这属于中观层级的共生关系;基于理性信任的人-机(技)共生关系构建则从存在论的维度将欺骗性价值对齐的应对延伸到人类未来之中,即走向宏观层级的共生,这种共生关系形成了应对欺骗性价值对齐风险的最大场域。
参考文献
[1]Russow L M. Deception: A philosophical perspective[C]∥Mitchell R W, Thompson N S. (eds.) Deception, perspectives on human and nonhuman deceit. New York: State University of New York Press,1986:48.
[2]Bond C F, Robinson M. The evolution of deception[J]. Journal of nonverbal behavior, 1988,12(4): 295-307.
[3][美]斯蒂芬·沃尔弗拉姆 .这就是ChatGPT[M].WOLFRAM传媒汉化小组,译.北京:人民邮电出版社,2022:40.
[4]Hurt A. Are humans the only animal that lies? [EB/OL]. (2022-03-26) [2024-06-28]. https:∥www.discovermagazine.com/planet-earth/are-humans-the-only-animals-that-lie.
[5]Berglund L, Stickland A C, Balesni M, et al. Taken out of context: On measuring situational awareness in LLMs[EB/OL]. ArXiv,abs/2309.00667. (2023-09-01) [2024-06-28]. https:∥arxiv.org/abs/2309.00667.
[6]Rosenblueth A, Wiener N, Bigelow J. Behavior, Purpose and teleology[J]. Philosophy of science,1943,10(1):18-24.
[7]Sarkadi S, Mei P, Awad E. Should my agent lie for me?Public moral perspectives on deceptive AI[C]∥Amigoni F, Sinha A. (eds) Autonomous agents and multiagent systems. Cham: Springer,2023:174.
[8]Biggio B, Roli F. Wild patterns: Ten years after the rise of adversarial machine learning[J]. Pattern recognition,2018,84: 317-331.
[9][意]西蒙尼·纳塔莱.媒介欺骗性:后图灵时代的人工智能和社会生活[M]. 汪让, 译.上海:复旦大学出版社,2023.
[10]Turing A M. Computing machinery and intelligence[J]. Mind, 1950,59(236):433-460.
[11]Alinier G, Oriot D. Simulation-based education:Deceiving learners with good intent[J]. Advances in simulation,2022,7(1): 1-13.
[12]Krügel S, Ostermaier A, Uhl M. Zombies in the loop?Humans trust untrustworthy AI-advisors for ethical decisions[J]. Philosophy & technology,2022,35(1): 1-37.
[13]Kim T W, Hooker J, Donaldson T. Taking principles seriously: A hybrid approach to value alignment[J]. Journal of artificial intelligence research,2021,70: 871-890.
[14]闫宏秀,李洋. 价值对齐是人类通往未来的“必经之路”吗?[J].科学·经济·社会,2024(2):26-32.
[15]闫宏秀. 基于信任视角的价值对齐探究[J].浙江社会科学,2024(6):39-48+157.
[16]Darban M. Navigating virtual teams in generative AI-led learning: The moderation of team perceived virtuality [J]. Education and information technologies,2024. https:∥doi.org/10.1007/s10639-024-12681-4.
[17]Public Affairs Council. 2022 Public affairs pulse survey report: what Americans think about business and government [EB/OL]. (2023-09-30) [2024-06-28]. https:∥pac.org/wp-content/uploads/2022/09/Pulse_Survey_Report_2022.pdf.
【本文原载于《华中科技大学学报(社会科学版)》2024年第5期,澎湃新闻经授权转载】
喜欢"人工智能价值对齐的哲学反思|探寻欺骗性价值对齐的应对逻辑:从“意图”到“共生”"的人也看了
-
走你,小五--微博时代原创超人气漫画家丁一晨真挚新作 pdf mobi txt word epub 下载 2024
-
探秘《山海经》:古籍中的奇幻世界与现代视角下的多元解读
-
人工智能价值对齐的哲学反思|有限主义视域下的人工智能价值对齐
-
新辑中国古版画丛刊:玉茗堂批评红梅记 pdf mobi txt word epub 下载 2024
-
人工智能价值对齐的哲学思考|价值嵌入与价值对齐:人类控制论的幻觉
-
防雷与接地技术概论 刘刚,邓春林 编著 华南理工大学出版社【正版可开发票】 pdf mobi txt word epub 下载 2024
-
澎湃思想周报|AI关乎权力而非技术;心理治疗机器人的悖论
-
济南市交通旅游图(亚洲杯版) pdf mobi txt word epub 下载 2024
-
罪恶而欢乐:莱茵河畔的狂欢节政治
-
小学数学评价与命题宇丛轩图书 pdf mobi txt word epub 下载 2024
- 心胜123:掌握内心力量,引领成功之路
- 中学教材全解 八年级物理上 广东教育上海科技版 2018秋 pdf mobi txt word epub 下载 2024
- 《王子与贫儿》:跨越身份的奇迹与永恒的人性光辉
- 探讨贪污贿赂渎职罪:法律框架、案例分析与预防策略
- 数据化决策 pdf mobi txt word epub 下载 2024
- 掌握CAXA制造工程师2008:从入门到精通的全方位指南
- Visual Fortho数据库程序设计实训:从入门到精通
- 诗人帝王 pdf mobi txt word epub 下载 2024
- 新时代保险业的革新:从技术创新到生态构建
- 外汇黄金投资指南 pdf mobi txt word epub 下载 2024
- 消防安全技术实务 pdf mobi txt word epub 下载 2024
- 伊川击壤集 【正版保证】 pdf mobi txt word epub 下载 2024
- 掌控情绪的力量:提升情绪智能,享受更加丰富多彩的人生
- 探秘《山海经》:古籍中的奇幻世界与现代视角下的多元解读
- 一周文化讲座|AI时代,读文科还有什么用?
- 钱谦益的身后名
- 圆桌|陈楸帆、糖匪、刘希:AI时代的性别、身份和边界
- 1分钟超强笔记术 pdf mobi txt word epub 下载 2024
- 哎呀疼医生(注音全彩美绘版) pdf mobi txt word epub 下载 2024
- 澎湃思想周报丨美国的学术自由与学术抵制;双面阿兰·德龙